timestamp, event_type, and value.
It aims to calculate a rolling 5-minute count and sum of value for each event_type using a tumbling window. Then, the logic will be modified to calculate an average, showcasing how SQLMesh handles the change.
Set up RisingWave and ingest sample data
Begin by starting RisingWave and manually inserting sample data into a base table.-
Start RisingWave via Docker.
The message of
RisingWave standalone mode is readymeans that RisingWave has started successfully. -
Connect via
psql(or another Postgres-compatible SQL client) and prepare the data.Insidepsql, run the following:
Set up SQLMesh project
Set up the SQLMesh environment to manage our RisingWave transformations.-
Create a project directory and Python virtual environment.
-
Install the SQLMesh RisingWave adapter:
-
Initialize the SQLMesh Project specifically for RisingWave:
This creates necessary folders and configuration files.
-
Configure the connection in
config.yamlfile (created byinit). Ensure the following matches or update yourconfig.yaml.
Define and deploy a streaming query (v1)
Create the first transformation model and deploy it.-
Create the SQLMesh model file
models/event_summary_tumbling.sql: -
Plan and apply the model using SQLMesh:
SQLMesh will detect the new model (
reporting.event_summary_tumbling) and show a plan to create it in the prod environment (which maps to a schema likesqlmesh_prodorprodin RisingWave, often including the model name itself, e.g.,sqlmesh__reporting). It will also detect the default models created by init; you can choose to apply changes only for your new model if desired, or apply all.SQLMesh executes theCREATE MATERIALIZED VIEWstatement(s) in RisingWave. -
Verify the MV creation and content via
psql. The exact schema and MV name includes a hash for versioning. You can useSHOWto find it. Sincereportingis used as model schema, the materialized view should be in thesqlmesh__reportingschema.You should see the aggregated results similar to below.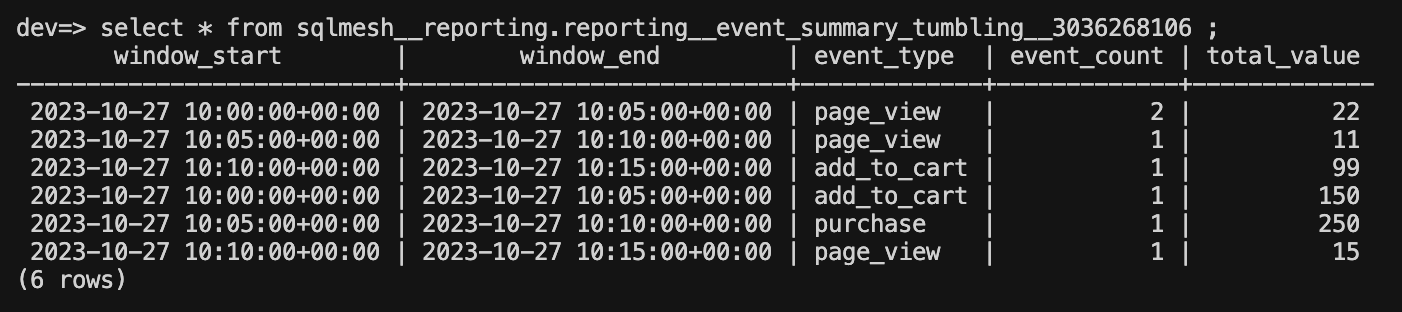
Modify the MV schema with SQLMesh (v2)
Now we can change the aggregation logic and see how SQLMesh manages the update safely.-
Modify the model file
models/event_summary_tumbling.sqlto calculate the average value and distinct count: -
Run
sqlmesh planagain to see the impact. SQLMesh detects the change in the definition ofreporting.event_summary_tumbling. Because the logic changed, it plans to:- Create a new version of the Materialized View in RisingWave with a different physical name (a new hash suffix).
- It does not immediately drop the old version, allowing for validation or zero-downtime promotion strategies (though in this simple apply, the old one might eventually be cleaned up depending on settings).
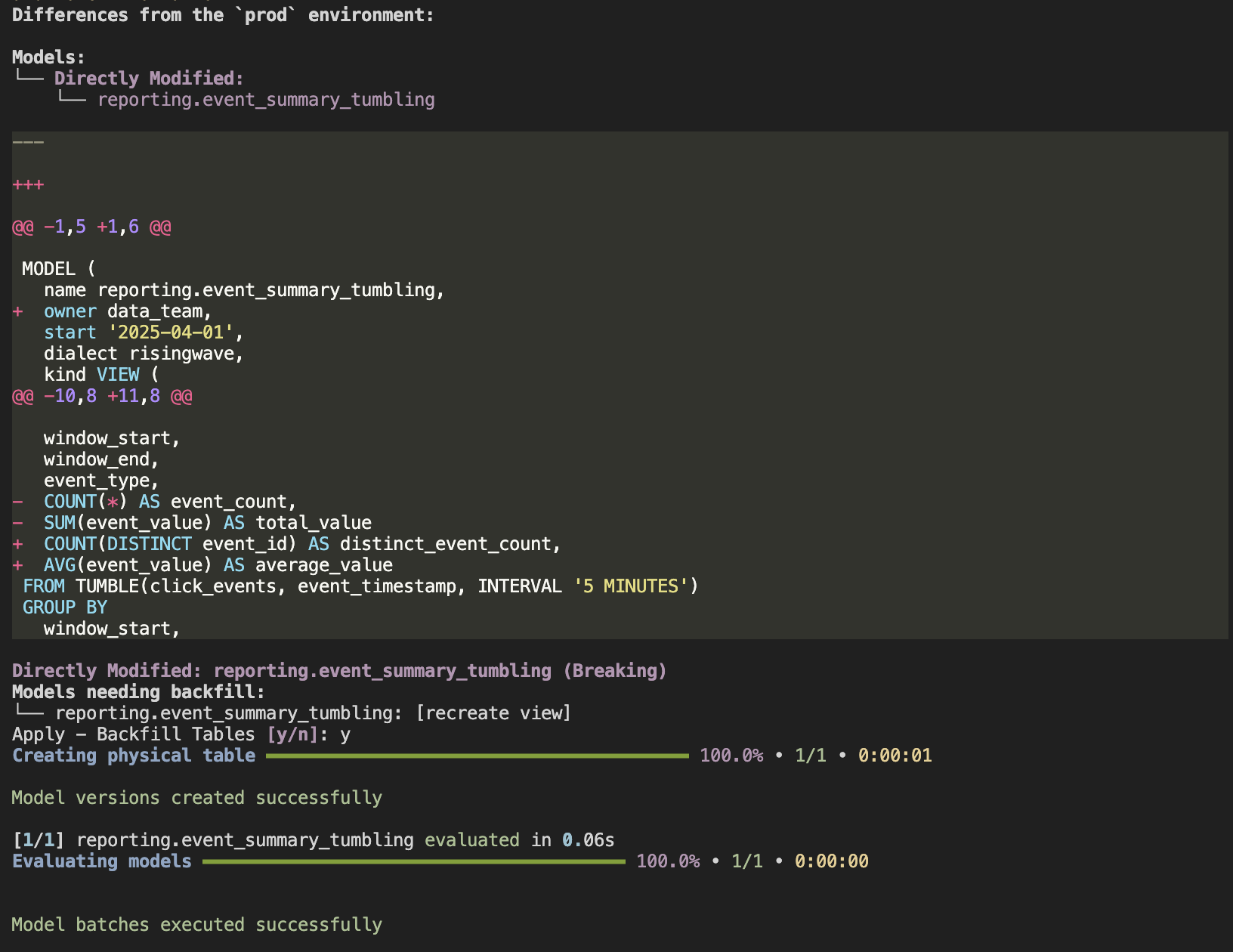
-
Verify the new MV version via
psql:The results should show thedistinct_event_countandaverage_value columns, reflecting the v2 logic. The original v1 MV still exists momentarily. This demonstrates SQLMesh’s safe, versioned deployment approach.
Integrate sink and source management
This guide manually created theclick_events table in RisingWave for simplicity. However, SQLMesh provides pre- and post-statements within model definitions, allowing you to embed DDL statements that run before or after the main model logic executes.
For example, you could place a CREATE SOURCE IF NOT EXISTS ... statement in pre-statement (that is, a SQL query prior to the SELECT statement), and / or a CREATE SINK IF NOT EXISTS ... in a post-statement. This approach keeps the setup/teardown logic closer to the relevant transformation step within your SQLMesh project.
SQLMesh’s core focus is managing the transformation logic (the SELECT statements) and dependencies across your entire pipeline (often multiple models). While pre- and post-statements offer integration points, managing complex CREATE SOURCE/SINK statements with intricate connector configurations might still be cleaner handled outside the model definitions (e.g., separate setup scripts or specialized infrastructure tools) to maintain clarity.