Serverless backfilling is available starting from v2.8.0 and is disabled by default.
Overview
When you create a materialized view (MV), sink, or index on existing data, RisingWave must first process all historical records, a phase called backfill. By default, this runs on the same compute nodes as your regular streaming workloads, which can cause resource contention and increased latency for existing pipelines. Serverless backfilling runs the backfill phase on dedicated backfiller resources — a temporary resource group that RisingWave Cloud provisions separately from your main streaming compute nodes. It is serverless because you don’t manually allocate or manage resources for each new job: after theCREATE MATERIALIZED VIEW, CREATE SINK, or CREATE INDEX request passes validation and the streaming job is ready to be created, RisingWave Cloud provisions the backfiller resource group and destroys it automatically once the job completes. Failed validation paths therefore do not provision backfiller resources. This decoupling helps large backfills complete while reducing their impact on the performance of existing streaming jobs.
Serverless backfilling is supported only in RisingWave Cloud. Enable it in the Backfilling section of the Resources page in the Cloud console first. See Configure serverless backfilling for portal setup, SKU, and replicas.
How it works
When serverless backfilling is enabled for aCREATE MATERIALIZED VIEW, CREATE SINK, or CREATE INDEX statement:
- After RisingWave finishes validation and is about to issue the create streaming job command, the serverless backfilling controller provisions a temporary resource group with dedicated backfiller nodes, sized by the Backfiller SKU and replica count you configure in the Cloud console.
- The backfill job runs on those dedicated backfiller nodes, separately from your main streaming compute nodes, so it doesn’t compete with existing streaming jobs for resources.
- Once all backfill fragments report completion, the job transitions to its standard steady-state resource group (the resource group of its parent database) for normal streaming execution.
- If the cluster restarts during backfill, the job resumes from the last completed checkpoint rather than starting over.
Configuration
You must enable serverless backfilling in the RisingWave Cloud console (in the Backfilling section of the Resources page) before using it. If it isn’t enabled,CREATE MATERIALIZED VIEW, CREATE SINK, and CREATE INDEX statements that request serverless backfilling return an error.
Session variable
Enable serverless backfilling for subsequentCREATE MATERIALIZED VIEW, CREATE SINK, and CREATE INDEX statements in the current session:
false. This setting only affects new DDL operations issued after the SET command; it does not change the behavior of already-running jobs.
If you set
enable_serverless_backfill through dbt, use dbt-risingwave 1.11.4 or later. Earlier versions of the plugin do not apply this session variable.Per-statement WITH clause
You can also enable serverless backfilling for a singleCREATE MATERIALIZED VIEW, CREATE SINK, or CREATE INDEX statement using the cloud.serverless_backfill_enabled option in the WITH clause:
WITH clause:
Example
The following example creates a large materialized view with serverless backfilling enabled to reduce the impact of the backfill on existing streaming workloads:Example: serverless backfilling
Monitor progress
Monitoring
Use the following system catalog and metrics to track serverless backfilling jobs:
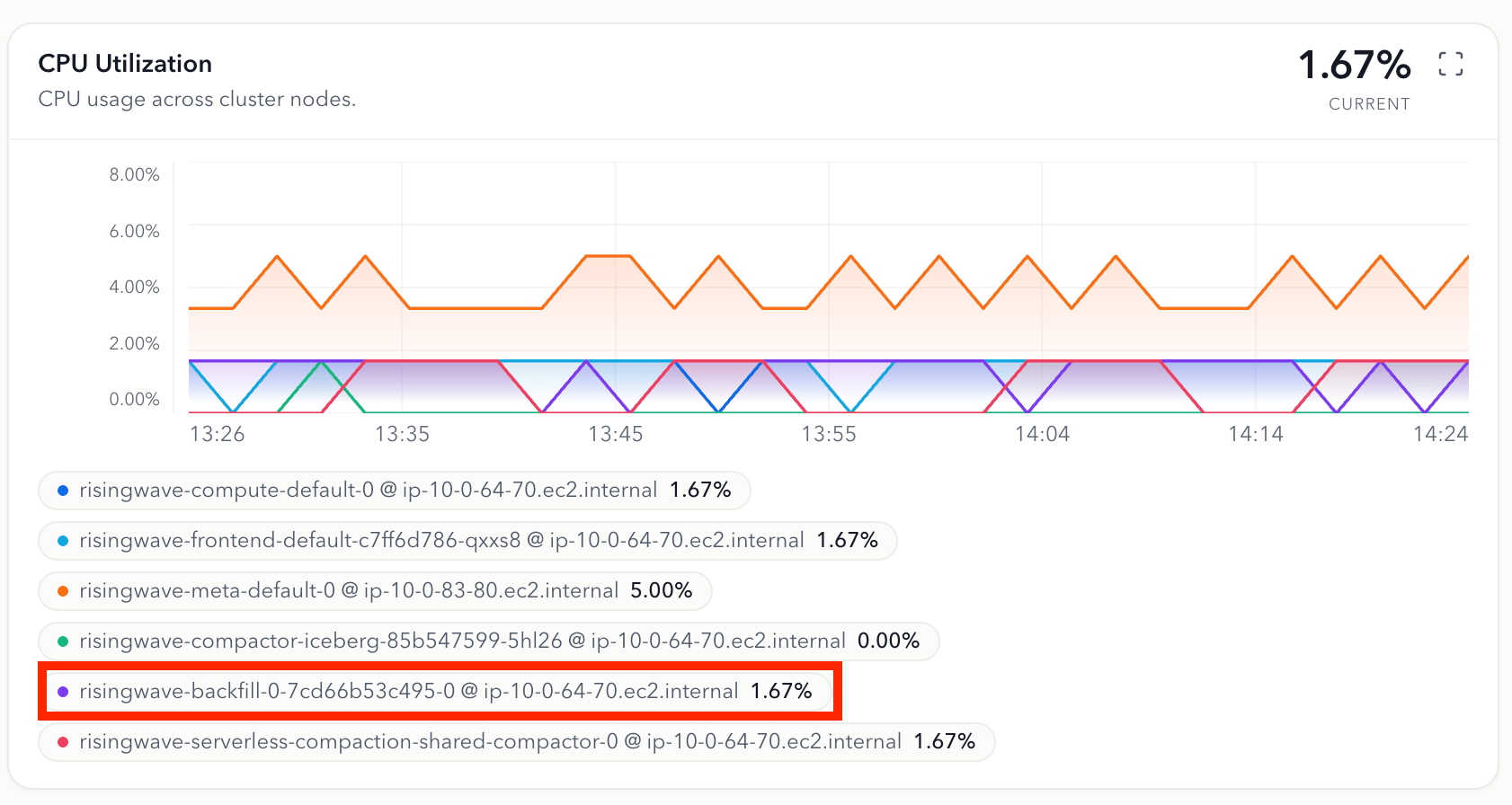
For example, the CPU Utilization panel below (on the Cloud portal Metrics page) lists each cluster node. The highlighted
risingwave-backfill-0-* series is a dedicated backfiller node that RisingWave Cloud provisions for the serverless backfilling job, separate from your main compute nodes (risingwave-compute-*).
Limitations
- Serverless backfilling is supported only in RisingWave Cloud, and you must enable it in the Backfilling section of the Resources page before requesting it in SQL.
Related pages
- Configure serverless backfilling — Set the backfiller SKU, replicas, and other Cloud setup.
- Backfill — Overview of all backfill strategies in RisingWave.
- SET BACKGROUND_DDL — Run DDL operations in the background without blocking the client.
- CREATE MATERIALIZED VIEW — Full syntax and options for creating materialized views.
- CREATE SINK — Full syntax and options for creating sinks.
- CREATE INDEX — Full syntax and options for creating indexes.
- View and configure runtime parameters — All session variables, including
enable_serverless_backfill.