Can RisingWave replace Flink SQL?
Yes. RisingWave is a superset of Flink SQL in terms of capabilities. Users of Flink SQL can easily migrate to RisingWave. RisingWave also offers additional features not present in Flink SQL, such as cascading materialized views that allow you to build multi-layered streaming pipelines entirely in SQL.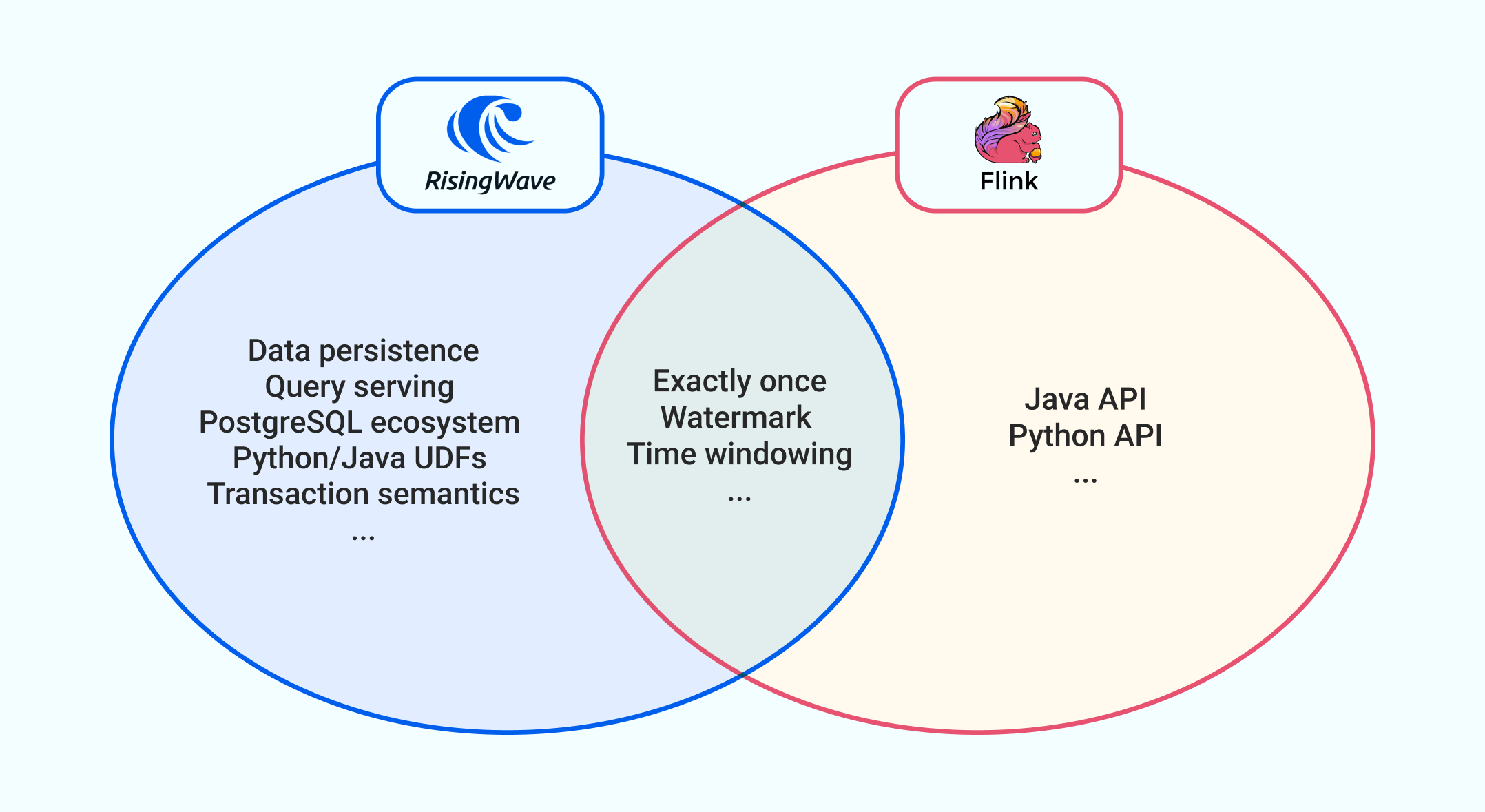
Is RisingWave a unified batch and streaming system?
Yes, RisingWave fully supports both stream processing and batch processing. Stream processing refers to continuous incremental computation on newly inserted data, while batch processing refers to computation on already stored data. RisingWave shines in stream processing. Regarding storage format, RisingWave utilizes a row-based storage engine (Hummock), which is optimized for point queries on stored data rather than full table scans. If you have a significant need for ad-hoc full-table analytical queries, we recommend complementing RisingWave with OLAP databases like ClickHouse or Apache Pinot — or using RisingWave’s native Apache Iceberg support to export data into a columnar format.Does RisingWave support transaction processing?
RisingWave supports read-only transactions but does not support read-write transaction processing. RisingWave is not designed to replace PostgreSQL or MySQL for OLTP workloads. This is a deliberate design choice: in production environments, dedicated transactional databases are typically required to support online business operations. Combining transaction processing and stream processing within the same database would introduce complexity and make it challenging to optimize for both. Best practice: Position RisingWave downstream from your transactional database. Use Change Data Capture (CDC) to replicate serialized data from PostgreSQL, MySQL, or other transactional databases into RisingWave for real-time stream processing.Why does RisingWave use row-based storage for tables?
RisingWave uses row-based storage (Hummock) because the same storage engine serves both internal state management for streaming queries and data storage for serving queries. Row-based storage is well-suited for:- Streaming state management: Storing operators’ internal state such as hash tables, aggregation buffers, and join state efficiently.
- Point queries: Ad-hoc queries on stored data that look up specific rows by key, which is a common access pattern for serving workloads.
Can a streaming database be considered as a combination of a stream processing engine and a database?
No. A streaming database like RisingWave is not simply the merging of a stream processing engine (e.g., Apache Flink) and a database (e.g., PostgreSQL). Here are the key differences:- Unified storage: A streaming database uses one storage system for managing internal state, storing results, and serving queries. An independent database is unsuitable for storing streaming internal state due to the high overhead and latency of frequent cross-system data access.
- Cascading materialized views: This is a core feature of streaming databases. Emulating this with separate systems would require additional components like Kafka to facilitate message passing between materialized views.
- Built-in consistency: Ensuring consistency across multiple independent systems requires significant engineering effort. A streaming database provides this natively.
- Operational simplicity: Managing one integrated system incurs far lower operational costs than managing multiple systems (stream processor + message queue + database).
- Seamless user experience: One SQL interface for defining streaming pipelines, querying results, and managing data — instead of learning and operating multiple tools.
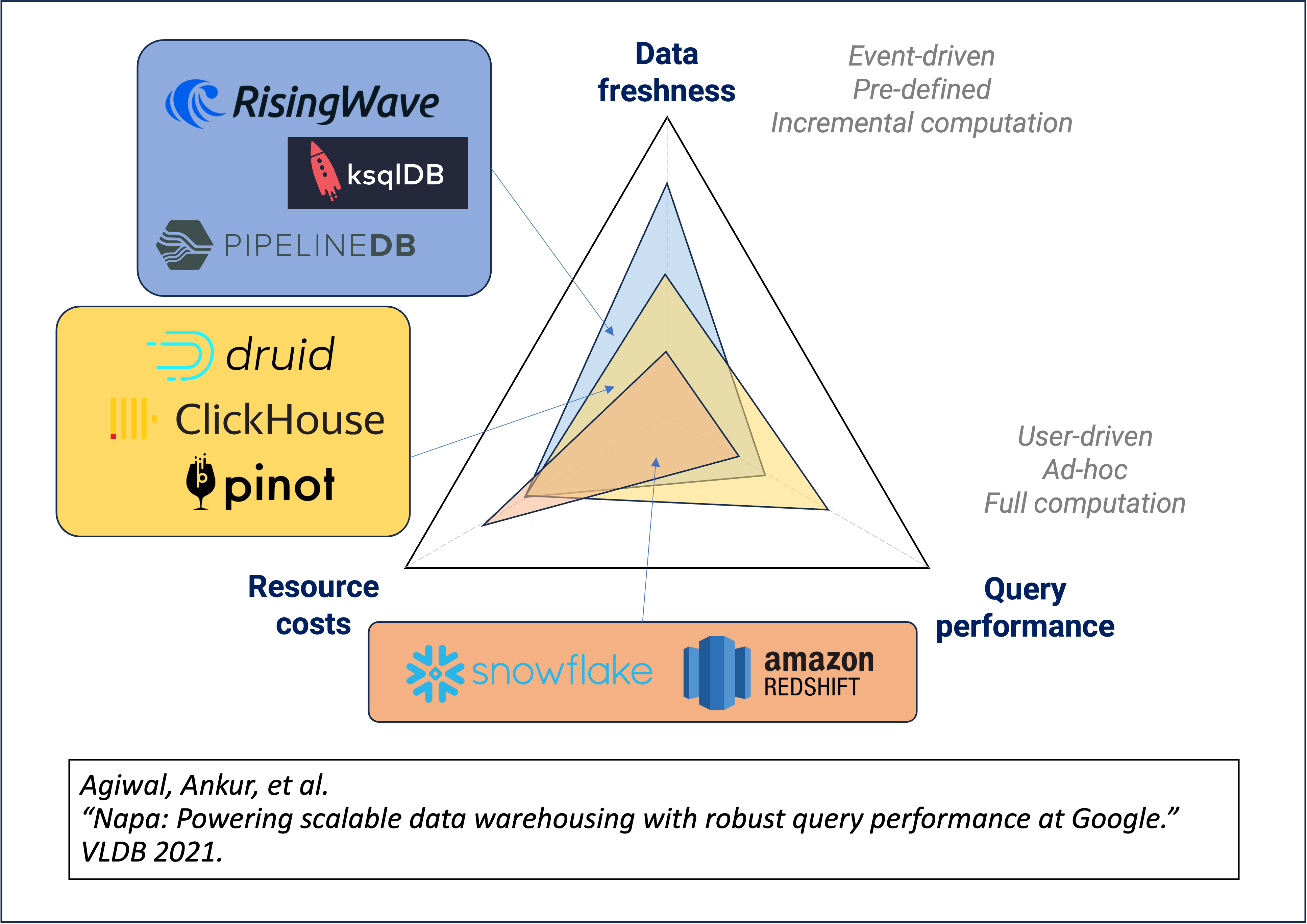
What are the differences between streaming databases and real-time OLAP databases?
Streaming databases (like RisingWave, ksqlDB) and real-time OLAP databases (like ClickHouse, Apache Pinot, Apache Druid) serve different primary use cases:
According to the Napa paper by Google engineers, any system can only optimize two out of three aspects: freshness of results, performance of ad-hoc queries, and resource costs. Streaming databases optimize for result freshness, while OLAP databases optimize for ad-hoc query performance.
How do materialized views in RisingWave differ from those in OLAP databases?
Materialized views in RisingWave are fundamentally different from those in OLAP databases like ClickHouse or Apache Druid:
Key advantages of materialized views in RisingWave:
- Real-time: Updated synchronously as upstream data changes — no manual refresh needed.
- Consistent: Correct results across multiple cascading materialized views.
- Highly available: Persisted to object storage with frequent checkpoints for fast failure recovery.
- Resource isolation: Streaming computation and ad-hoc queries can run on separate node groups to avoid interference.